
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Meaningful uncertainty quantification in computer vision requires reasoning about semantic information— say, the hair color of the person in a photo or the location of a car on the street. To this end, recent breakthroughs in generative modeling allow us to represent semantic information in disentangled latent spaces, but providing uncertainties on the semantic latent variables has remained challenging. In this work, we provide principled uncertainty intervals that are guaranteed to contain the true semantic factors for any underlying generative model. The method does the following: (1) it uses quantile regression to output a heuristic uncertainty interval for each element in the latent space (2) calibrates these uncertainties such that they contain the true value of the latent for a new, unseen input. The endpoints of these calibrated intervals can then be propagated through the generator to produce interpretable uncertainty visualizations for each semantic factor. This technique reliably communicates semantically meaningful, principled, and instance-adaptive uncertainty in inverse problems like image super-resolution and image completion. |
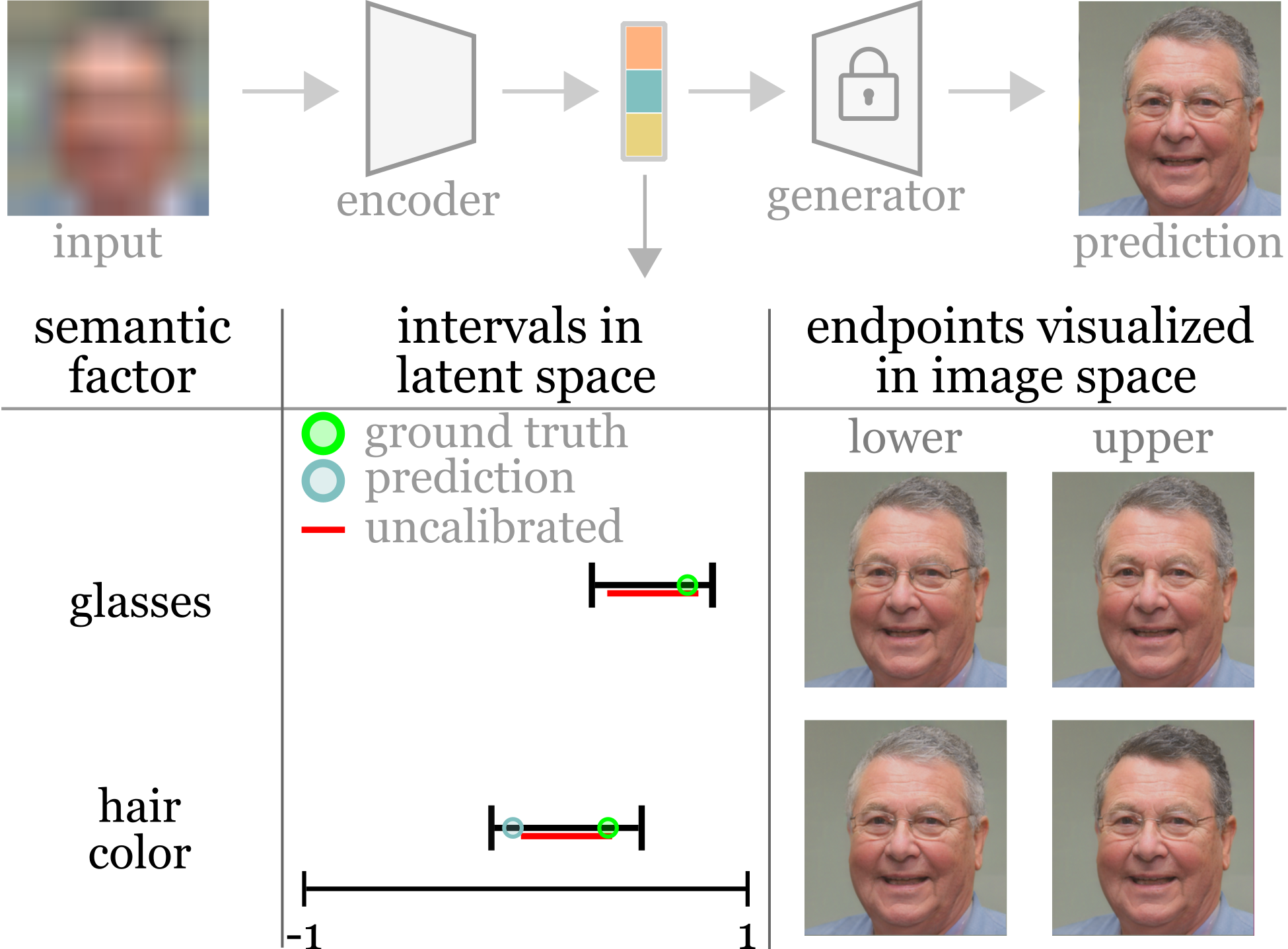
| Our work addresses the problem of directly giving uncertainty estimates on semantically meaningful image properties. We make progress on this problem by bringing techniques from quantile regression and distribution-free uncertainty quantification together with a disentangled latent space learned by a generative adversarial network (GAN). We call the coordinates of this latent space semantic factors, as each controls one meaningful aspect of the image, like age or hair color. Our method takes a corrupted image input and predicts each semantic factor along with an uncertainty interval that is guaranteed to contain the true semantic factor. When the model is unsure, the intervals are large, and vice-versa. By propagating these intervals through the GAN coordinate-wise, we can visualize uncertainty directly in image-space (shown left) without resorting to per-pixel intervals. The result of our procedure is a rich form of uncertainty quantification directly on the estimates of semantic properties of the image. |
 |
 |
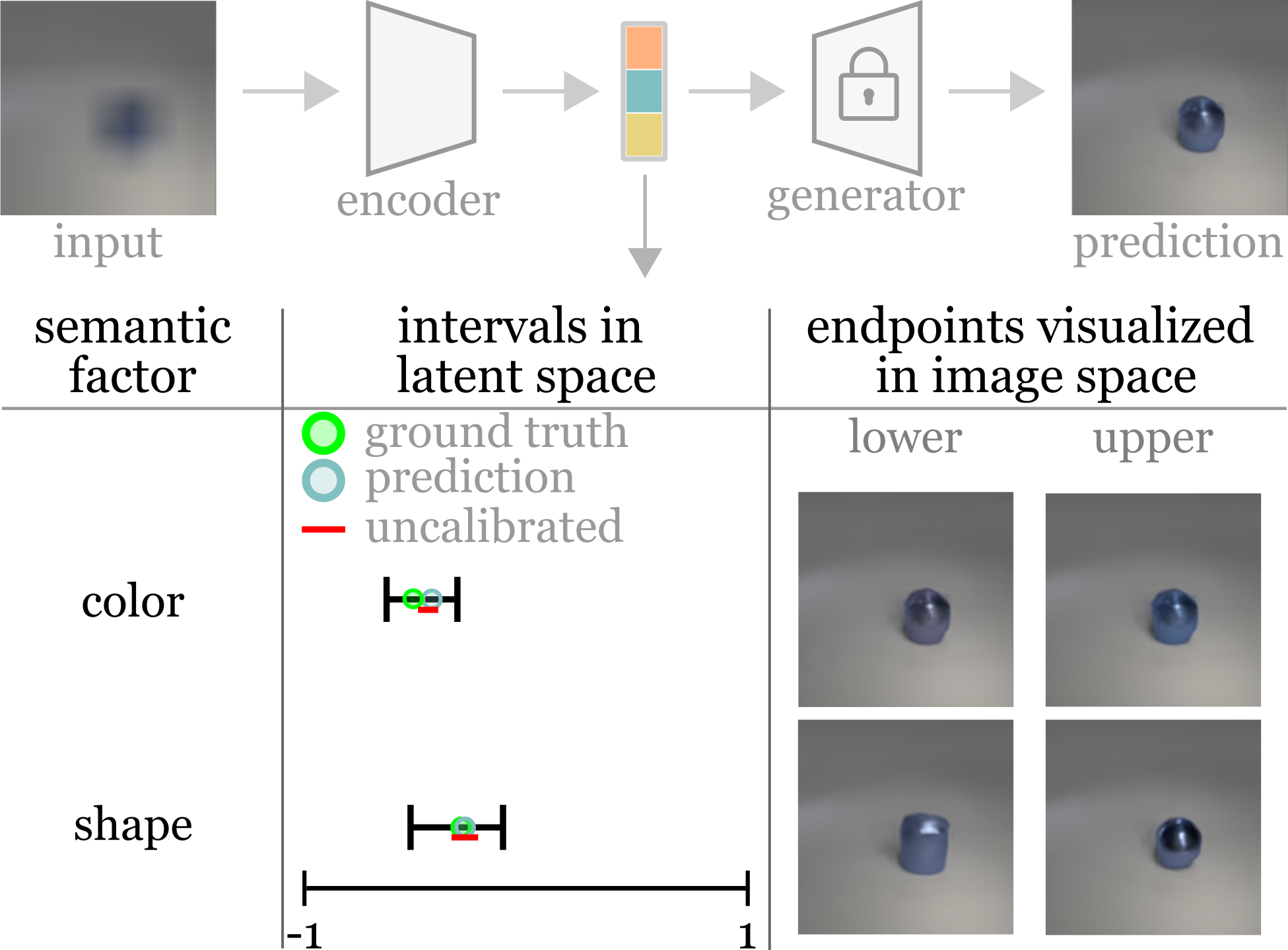
| The image on the left shows a uncertainty prediction output on a sample drawn from the CLEVR dataset trained generative model. The uncertainty factors naturally into the latent factors, we visualize shape and color here. The lower and upper quantile images yield similar colors, which is predictable from the blurry input. The model predicts that both a cylinder and sphere would be consistent with this blurry input. The calibrated quantiles cover the ground truth color value while the uncalibrated ones do not. |

|

|
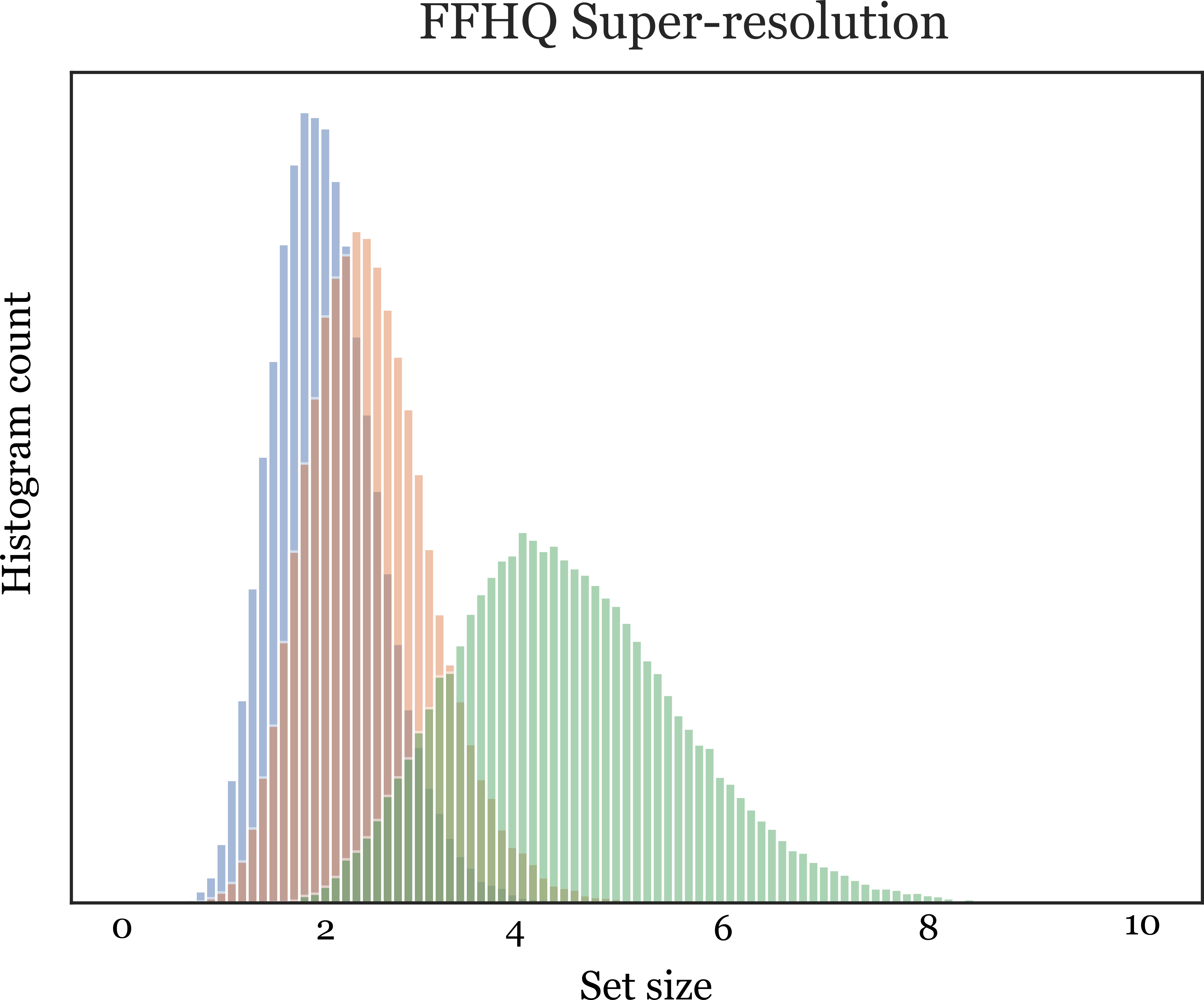
For the image super-resolution case, the corruption intensity is varied across each set, the input image in the top row is not corrupted while the input in the bottom row is under-sampled by 16x. In both cases,
we can observe that the most diverse prediction is in the bottom row where the input is corrupted the most.
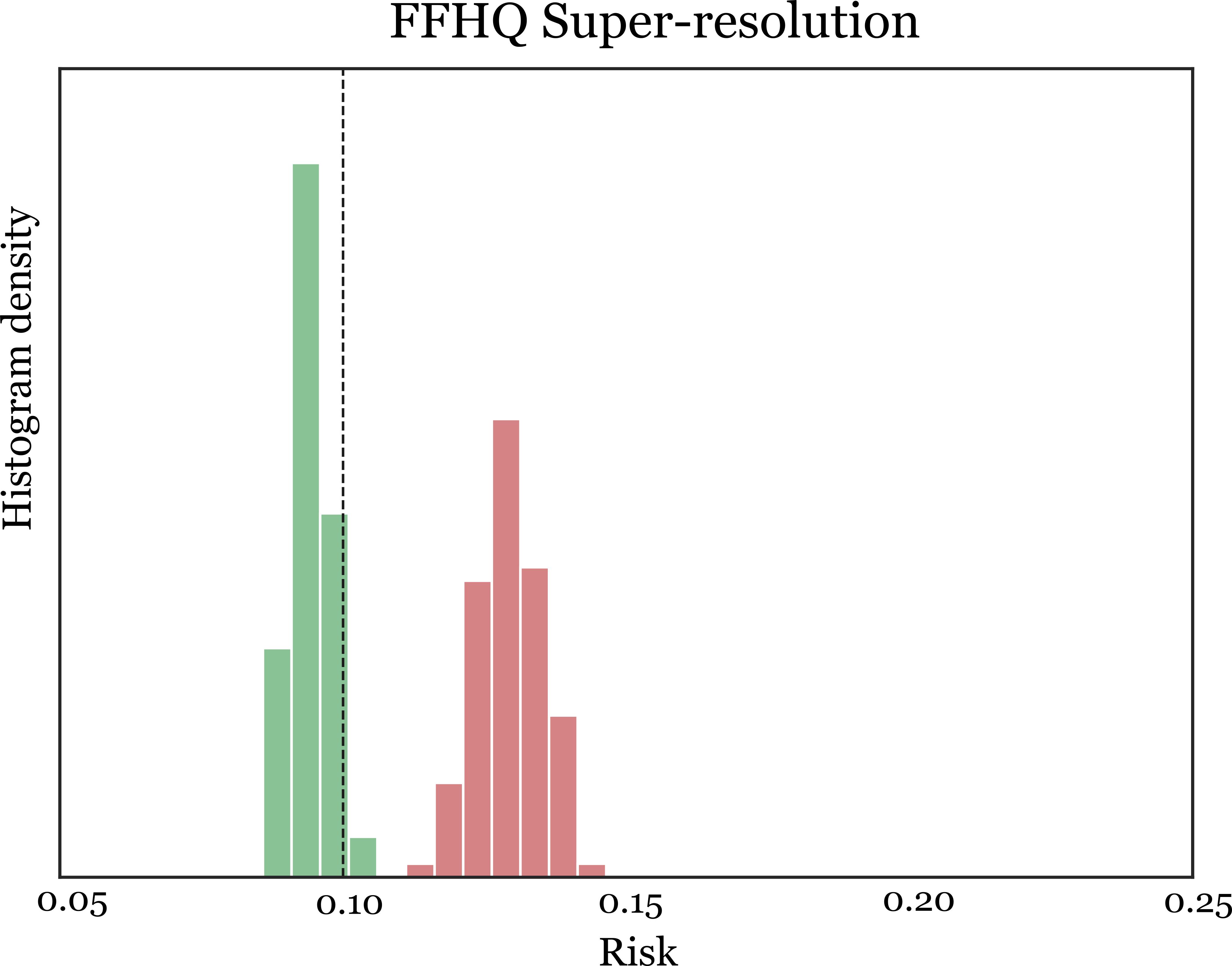
For the image inpainting case, a random mask is applied to the same input image in each row. When there is no mask (1st row), both quantiles are extremely close to the pointwise prediction.
As we increase the regions that are being masked, the predicted intervals expand, as indicated by the variability on the quantile predictions.
|
|
AcknowledgementsSankaranarayanan's and Isola’s research for this project was sponsored by the U.S. Air Force Research Laboratory and the U.S. Air Force Artificial Intelligence Accelerator and was accomplished under Cooperative Agreement Number FA8750-19-2- 1000. MIT SuperCloud and the Lincoln Laboratory Supercomputing Center also provided computing resources that contributed to the results reported in this work. Angelopoulos was supported by the National Science Foundation. Bates was supported by the Foundations of Data Science Institute and the Simons Institute. Romano was supported by the Israel Science Foundation and by a Career Advancement Fellowship from Technion. |